Seblod: SEO in List and Search Types
Berücksichtigt man den SEO Aspekt einer Webseite und hat man Seblod im Einsatz, stellt man bald ein Problem fest: Beim List & Search Type werden sehr viele URL erzeugt, welche nachteilig im SEO Ranking der Seite sind. Diese Lösung zeigt auf, wie man den List & Search Type SEO fit macht.
Nachträglicher Hinweis (30.07.16): Mittlerweile hat Seblod im Core implementiert, dass Suchergebnisse also URLs mit Suchparamentern generell auf Noindex, Nofollow stehen (getestet mit Seblod 3.8.4). Daher ist ein Einsatz dieser Lösung, dann noch sinnvoll, wenn Pagination (Seitennummerierungen), also Seite 2, Seite 3 auf Noindex stehen sollen. Dies lässt sich aktuell über den Seblod Core noch nicht steuern.
Das grundsätzliche Problem
List & Search Types bietet flexible Möglichkeiten Inhalte darzustellen und ersetzt die Standard Kategorie und Listenansicht in Joomla. Auf Grundlage individuell konfigurierter Felder und Suchabfragen, können die Inhalte dargestellt werden. Das Problem, welches hier einhergeht, ist dass eine riesige Anzahl von URLs erzeugt werden. Die Anzahl hängt von den eingesetzten Feldern unter Komplexität des "Search Forms" ab.
Beispiel
Dieses Beispiel zeigt die Problematik auf. Wir entwickeln eine Seite die Fahrzeuge verschiedener Marken darstellt. Hierzu haben wir einen individuellen Form & Content Type für Fahrzeuge entwickelt. Ein Feld aus diesem Formular definiert, um welche Marke es sich handelt. Auf der Homepage stellen wir nun sortiert nach Marke die Fahrzeuge dar. Hier das übliche Procedere: Menüpunkte werden angelegt (basierend auf List & Search Type) mit den passenden Live-Values der einzelnen Marken. Daraus ergibt sich die Menü/Urlstruktur.
| BMW | http://www.example.com/bmw |
| Audi | http://www.example.com/audi |
| Honda | http://www.example.com/honda |
Auf jeder dieser Unterseiten (Landingpages) bieten wir weitere Suchoptionen an, die wir im List & Search Type zentral definiert haben. Als Beispiel nehmen wir mal das Feld Kraftstoff (Option: Diesel, Benzin, Elektro). Der Besuche kann also auf jeder Seite BMW, Audi, Honda jeweils die Darstellung auf die genannte Option eingrenzen. Nehmen wir die BMW Seite als Beispiel, ergeben sich dadurch weitere URLs, die dadurch generiert werden.
| BMW - Diesel | http://www.example.com/bmw?cck=cars&krafstoff=diesel |
| BMW - Benzin | http://www.example.com/bmw?cck=cars&krafstoff=benzin |
| BMW - Elektro | http://www.example.com/bmw?cck=cars&krafstoff=elektro |
In diesem Fall ergeben sich nur diese drei zusätzlichen URLs. In Summe sind es also vier, die Google zu diesem einem Menüpunkt indexiert. In der Praxis sind es jedoch mehrere Parameter. Hieraus ergeben sich schnell ein paar tausend Urls bis zu mehreren Millionen, da diverse Parameter möglich sind und diese an beliebiger Stelle in der URL stehen können. Es passiert, dass z. B. Google Urls indexiert, die nirgendwo auf der Seite verlinkt sind. Vermutlich experimentiert der Bot hier mit den URL Variablen. In diesem Fällen passiert es, dass Google mehrere Domains indexiert mit dem gleichen Inhalt. Die nachfolgenden URL haben den gleichen Inhalt, sind jedoch unterschiedliche Adressen, also klassischer Duplicate Content.
http://www.example.com/bmw?cck=cars&krafstoff=diesel
http://www.example.com/bmw?krafstoff=diesel&cck=cars
Drei große Probleme
Aus dieser Situation ergeben sich drei große Probleme:
Die Suchmaschine indexiert völlig falsche Darstellungen
Bezogen auf unser Beispiel, kann es passieren das unter dem Menüpunkt BMW auf einmal Audi Fahrzeuge gelistet werden. Der Grund hierfür ist, dass die Suchmaschine mit Parametern experimentiert und eine URL indexiert, die diese Darstellung ermöglicht und als Suchergebnis präsentiert.
Doppelte Inhalte führen zu schlechten Rankings
Wie zuvor erwähnt, werden durch die unterschiedlichen URLs und gleichen bzw. ähnlichen Inhalte unnötige Seiten indexiert. Daraus ergibt sich das Problem, dass die Wichtigkeit der eigentlichen Hauptseiten an Relevanz deutlich abnimmt. Schlechte Rankings sind die Folge. Zum Beispiel für unsere Hauptseite www.example.com/bmw.
Crawling Budget wird verbraten
Abhängig von der Größe/Wichtigkeit einer Seite investiert Google Energie, um Inhalte zu identifizieren. Veränderungen und neue Artikel werden hier beispielsweise festgestellt. Bei den Standardeinstellungen von Joomla und Seblod, wird die Suchmaschine angewiesen jede Seite in ihren Index aufzunehmen. Auf unser Beispiel bezogen: Hat nun bereits jeder unserer Menüpunkte viele tausende oder gar Millionen von URLs, so wird der Bot nicht zwangsläufig die gesamte Seite durchsuchen, da dies einen hohen Energieaufwand darstellt. Als Nachteil ergibt sich dadurch, dass Veränderungen sehr lange brauchen, bis sie im Google berücksichtigt werden.
Exkurs: Canonical
Mithilfe eines Canonical Tag, kann eine Empfehlung an die Suchmaschine abgegeben werden, welche URL tatsächlich indexiert werden soll. Es handelt sich jedoch lediglich um einen Hinweis, den die Suchmaschine nicht zwangsläufig beachtet. Prinzipiell dient der Canoncial doppelte Inhalte auf der Seite zu vermeiden. Beispielsweise gibt es eine Druckversion, die darauf hinweist dass der eigentliche Artikel unter einer anderen URL zu finden ist.
In der Regel wird der Canonical im HTML Tag <head></head> eingebunden, kann alternativ aber auch über den HTTP-Header mitgeteilt werden.
<link href="http://www.example.com" rel="canonical" />
Einsatz des Canonicals auf unser Beispiel bezogen:
| URL | Canonical-URL |
| http://www.example.com/bmw | http://www.example.com/bmw |
| http://www.example.com/bmw?cck=cars&krafstoff=diesel | http://www.example.com/bmw |
|
http://www.example.com/bmw?cck=cars&krafstoff=benzin |
http://www.example.com/bmw |
| http://www.example.com/bmw?cck=cars&krafstoff=elektro | http://www.example.com/bmw |
Exkurs: Robots <META> tag
Die Robots Meta Tags können auf jeder Seite separat definiert werden und geben Anweisung an den Suchmaschinen Bot. Zum einen gibt sie an, ob eine Seite indexiert (index) oder nicht indexiert (nofollow) werden soll. Zum anderen sagt sie dem Bot, ob er die Links auf der Seite verfolgen soll (follow) oder nicht (nofollow). Fehlt die Angabe auch einer Seite, geht die Suchmaschine von index, follow aus. Wie auch der Canonical, wird er im im HTML Tag <head></head> eingebunden.
<meta name="robots" content="index, follow" />
<meta name="robots" content="index, nofollow" />
<meta name="robots" content="noindex, follow" />
<meta name="robots" content="noindex, nofollow" />
Exkurs: Canonical Plugin Seblod
Das Canonical Plugin von Seblod ist kostenlos, löst aber unser Problem nicht. Der Vollständigkeit halber, wird es jedoch auch erwähnt.
Es wird eingesetzt, um einen Canoncial auf dem Content-View der Seite zu setzen, nicht jedoch im List & Search Type. Es ist ratsam das Plugin zu nutzen. Der Inhalt ist nämlich über die Joomla übliche URL Struktur erreichbar, wie auch über die Seblod Menüpunkte der List & Search Types. Macht man dort einen Fehler in der Linkdefinition, bäugt man durch dieses Plugin, falschen Indexierungen vor.
Lösung
Ziel ist es, dass nur die Laningpages aus unserem Beispiel indexiert werden. Also diese URLs.
| BMW | http://www.example.com/bmw |
| Audi | http://www.example.com/audi |
| Honda | http://www.example.com/honda |
Um dies zu erreichen wird ein Cononical auf jeder weiteren Variation des Menüpunktes gesetzt, der auf die Hauptseite verweist. Damit jedoch der Item-View der einzelnen Fahrzeuge auch indexiert wird, wird jede Seite mit dem Robots Tag "follow" gekennzeichnet. Da der Canonical nur eine Empfehlung ist und sich Suchmaschinen nicht zwangsläufig daran halten wird jede Seitenvariation auf "noindex" gesetzt. Die Hauptseite hingegen ist mit "index" definiert.
Anleitung
- Zur Verwirklichung wird das Code Pack Plugin benötigt, dass 30 € kostet.
- Gehe zum gewünschten List & Search Type auf das Search Form
- Hier legen wir nun ein Feld des Types "Before Render" an, dass wir auf die Position Hidden setzen
- Wir wählen im Feld Mode "Free". Der nachfolgende PHP Code kommt nun in die Textarea. Hinweis: Eine Deklaration als PHP Code ist nicht notwendig.
- Code
/***
* V0.2 SEOonList&Search
*
* Ziel ist eine saubere SEO Lösung für List & Search in Seblod
*
* Was macht dieser Code:
* Fügt als Canonical die URL des Menüpunktes auf allen Suchergebnisseiten ein.
* Setzt den den Robots Tag "nofollow" auf allen Suchergebnisseiten mit Ausnahme des Menüpunktes
*
* Https/Http wird bei Canonicals berücksichtigt, die gesamte Seite darf jedoch nur
* über eines der Protokolle erreichbar sein. Falls beide gewünscht, muss
* das Protokoll hier manuell für den Canonical definiert werden.
*
* Index/Noindex: Joomla setzt standarmäßig keinen Robot Tag auf Menüpunkte.
* Ist dieser jedoch im Joomla-Menüeinstellungen aktiviert, wird dieser ausgegeben.
* Der Robots Befehl für den Menüpunkt muss deaktiviert sein (auf Global stellen)
* da sonst zwei widersprüchliche Robotstag im Code sind.
*
* WICHTIG Dies ist eine individuelle Lösung, die nicht für jeden Fall sinnvoll ist.
* Es wird daher ein ausgiebiger Test empfholen, da eine falsche Einstellung des Robots Tags
* und des Canonicals verheerende Auswirkungen auf die Positionierung in Suchmaschinen haben
* kann.
***/
//Url Definitionen
$aktivmenuurl = JURI::current(); /* Url des Menüpunktes */
$echturl = !empty($_SERVER['HTTPS']) ? 'https://' : 'http://';
$echturl .= $_SERVER['HTTP_HOST'] . $_SERVER['REQUEST_URI']; /* Echte Url des Users */
//Robots Anweisung index oder noindex
if ($aktivmenuurl==$echturl) {
$indexnoindex = 'index';
} else {
$indexnoindex = 'noindex';
}
// Canonical einfügen
$doc =& JFactory::getDocument();
if ( !($doc instanceof JDocumentRaw) ) {
$doc->addCustomTag( '<link href="'.$aktivmenuurl.'" rel="canonical" />' );
}
//Robots einfügen
$doc =& JFactory::getDocument();
if ( !($doc instanceof JDocumentRaw) ) {
$doc->addCustomTag( '<meta name="robots" content="'.$indexnoindex.', follow" />' );
}
Testen
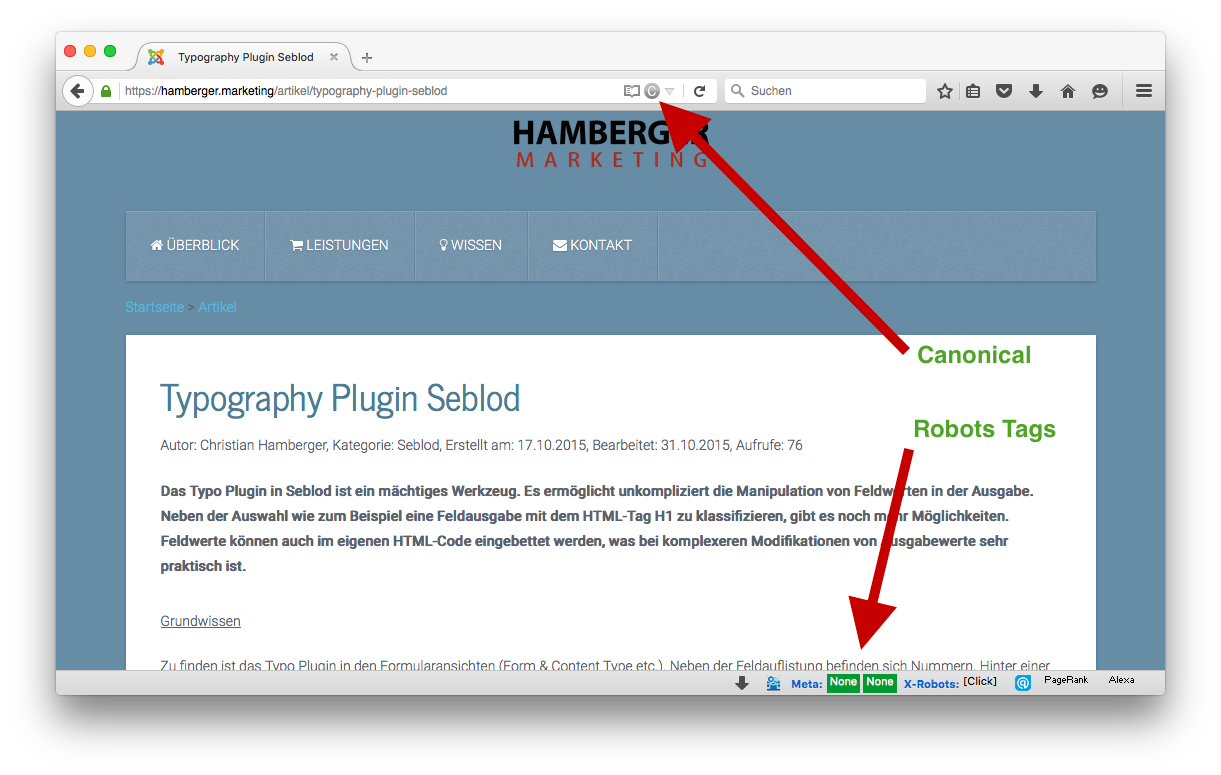
Zu guter Letzt sollte man unbedingt testen ob der gewünschte Effekt eintritt. Damit man nicht jedes Mal in den Code schauen muss, gibt es für den Firefox praktische Add-Ons. Hier sieht man auf einen Blick, wie die Robots Tags vergeben sind, ob ein Canonical vorhanden ist und wohin es zeigt.
Mit Seerobots werden die Robots Meta Tags angezeigt. Da es die Statusleiste in den neuen Firefox Browser nicht mehr gibt, installiert man hierfür zusätzlich das Add-On Status-4-Evar.
Mit dem Add-On SearchStatus sieht man wie der Canonical eingesetzt ist.
Ergänzung robots.txt
Alternativ gibt es auch andere Methoden Suchmaschinen von der Indexierung bzw. vom Crawlen abzuhalten. Suchergebnisse von Seblod laufen über den Parameter ?cck=. Daher kann dieser auch in der robots.txt unterdrückt werden.
Dieser Befehl verbietet es allen Crawlern auf URLs mit dem entsprechenden Seblod Parameter zuzugreifen. Falls sich jedoch Links auf diesen URLs befinden, die nur über diese zur Verfügung stehen und die indexiert werden sollen, kann diese Anweisung nachteilig sein. Im solch einem Fall werden diese Seiten vom Suchmaschinenbot gar nicht erst erreicht.
User-agent: *
Disallow: /*?cck=*
Die Anweisung eine Seite nicht zu indexieren, erfolgt standardmäßig auf Seitenebene über den Robots <META> Tag (s.h. oben). Laut einer Aussage von Matt Cutts akzeptiert Google auch in der robots.txt den Befehl. Dies stellt eine Alternative zum zu Disallow dar.
User-agent: *
Noindex: /*?cck=*
Tipp: Die Methode über die robots.txt stellt eine Alternative und somit eine zweite Lösung dar, wenn es schwer ist auf Seitenebene Indexierungsbefehle zu setzen.